来源 | CSDN
一、推荐系统简介
1 推荐系统背景
为了解决 信息过载 问题,在海量的数据中如何准确提供客户喜欢的内容。为了解决该问题,发展主要有三个阶段。
分类目录:1990s Hao 123 Yahoo
搜索引擎:2000s Google Baidu
推荐系统:2010s 不需要客户提供准确的信息,通过分析客户的历史行为来进行对用户的兴趣建模,从而提供客户满意的信息。
2 推荐和搜索的区别
搜索引擎:由用户主导,需要输入关键词,自行选择结果。如果结果不满意,需要修改关键词,再次搜索;注重搜索结果之间的关系和排序。
推荐系统:由系统主导,根据用户的浏览顺序,引导用户发现自己感兴趣的信息,需要研究用户的兴趣模型,利用社交网络的信息进行个性化的计算;
3 推荐系统的意义
主要有三个意义,分别从用户,内容提供者,平台
让用户更好的获取自己需要的内容
让内容更快更好的推动到适用人群
让平台跟有效的保留用户资源

4 推荐系统的应用
5 基本思想
知你所想,精准推送
利用用户和物品的特征信息,推荐具有这些特征的信息
物以类聚
利用用户喜欢的物品,推荐类似的物品
人以群分
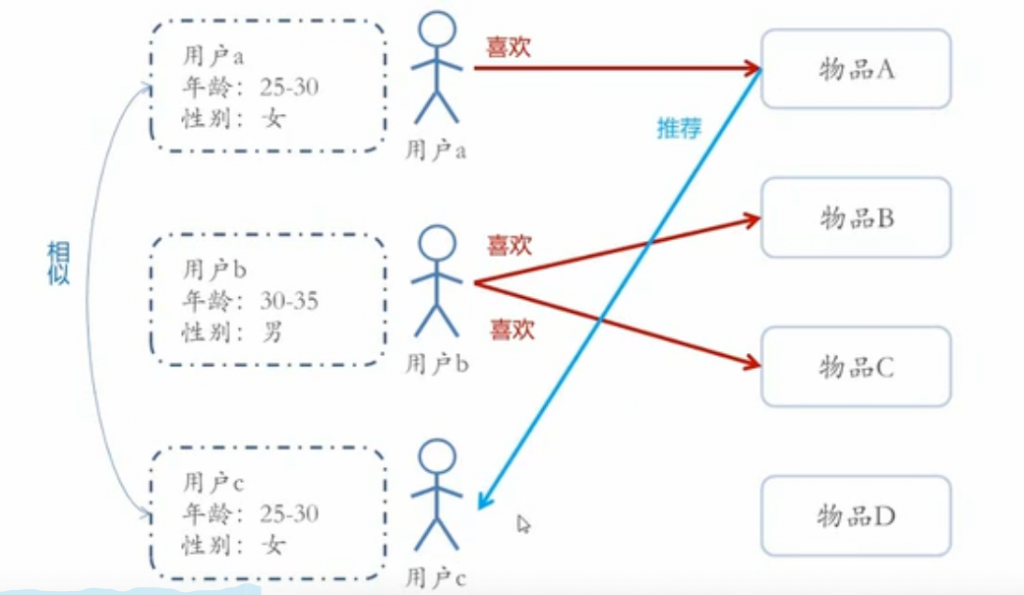
利用和用户相似的其他用户,基于他们的特征进行推荐
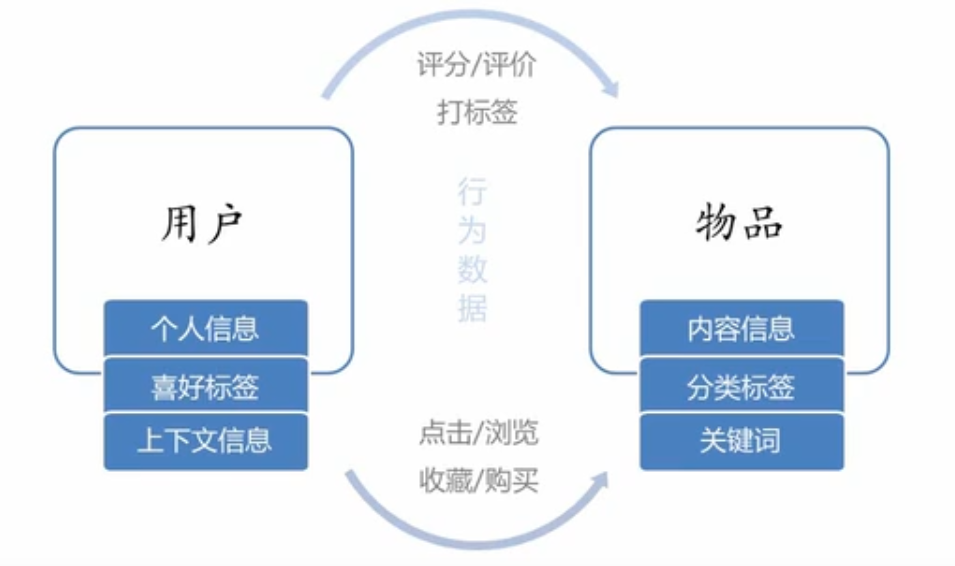
6 数据源
三类数据源: 用户,物品,行为数据
item数据:待推荐物品或内容的元数据,例如关键字,分类标签,基因描述等;
User 数据:用户的基本信息,例如性别,年龄,兴趣标签等;
行为数据:可以转化为对物品或者信息的偏好,根据应用本身的不同可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。这些用户的偏好信息可以分为两类:
显式的用户反馈:用户在网站上显式的反馈信息,例如用户对物品的评分,对物品的评论。
隐式的用户反馈:用户在使用网站是产生的数据,隐式的反应了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息等等。
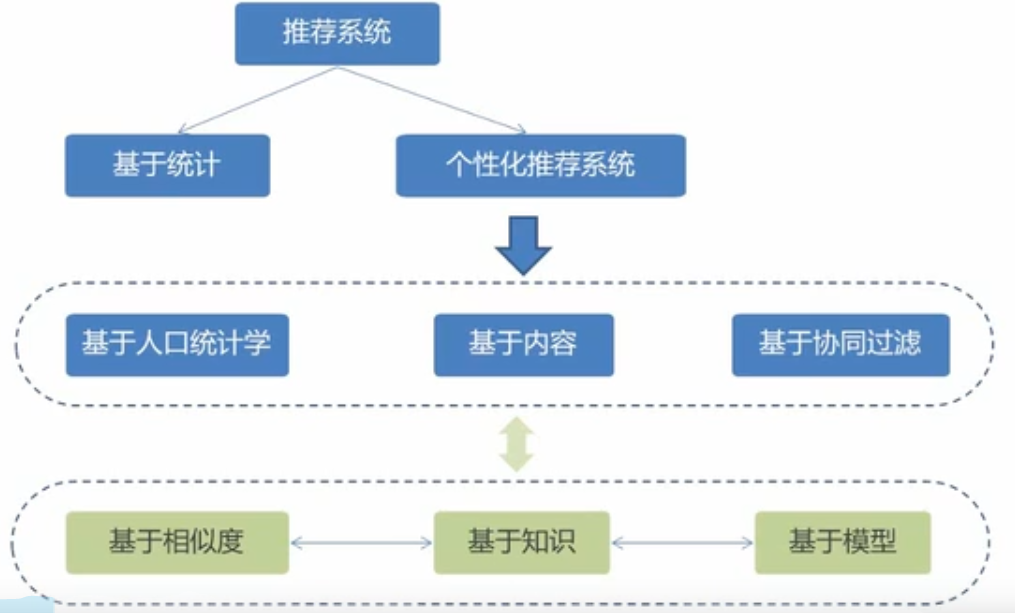
7 推荐系统的分类
1.根据实时性分类
离线推荐
实时推荐
2 是否个性化推荐
基于统计的
个性化推荐
3 根据推荐原则分类
基于相似度
基于知识
基于模型
4 根据数据源
基于人口统计学(用户信息)
基于内容的推荐(商品信息)
基于协同过滤的推荐 (基于行为数据)
1.基于人口统计学:
2.基于内容(Content Based,CB):
主要是利用用户评价过的物品内容的特征,CF还可以利用其他用户评价过的物品内容。
3.基于协同过滤:collaborative filtering,CF
基于近邻的协同过滤
基于用户(User-CF)
基于物品(Item-CF)
基于模型的协同过滤
奇异值分解(SVD)
潜在语义分解(LSA)
支持向量机(SVM)
4.混合推荐,就是集成学习(ensemble learning)
加权混合
对不同的推荐结果按照权重线性加权。
切换混合
多套推荐机制,根据系统的不同情况选择最合适的推荐机制。
分区混合
采用多种推荐机制,将不同的推荐结果推送到不同的用户。
分层混合
采用多种推荐机制,将一个机制的推荐结果作为另外一个的输入,类似boosting,串行学习。
二、推荐系统评测指标
根据评测体系来评价一个推荐系统的好坏,由于推荐系统是和实际收益挂钩,所以需要考虑三方(用户,物品提供者和平台)的利益,实现最大化的三方共赢。
接下来从实 验 方 法 , 评 测 指 标 和 评 测 维 度 \red{实验方法,评测指标和评测维度}实验方法,评测指标和评测维度进行介绍
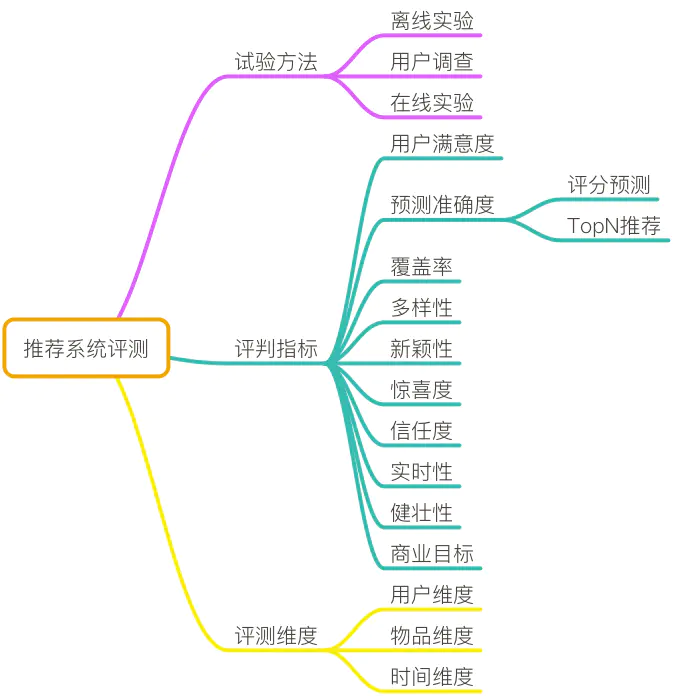
1 实验方法
通过实验来获取评价指标,主要有三个:
1.1 离线实验(offline experiment)
在一个离线的数据集上完成,不需要一个实际的系统作为支撑,只需要有一个从日志中提取的数据集即可。
1、步骤
a)通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
b)将数据集按照一定的规则分成训练集和测试集;
c)在训练集上训练用户兴趣模型,在测试集上进行预测;
d)通过事先定义的离线指标,评测算法在测试集上的预测结果。
2、优点
不需要用户参与
速度快,可以实验多种算法模型
不需要搭建一个完整的推荐系统
3、缺点
数据的稀疏性限制了适用范围,如果一个数据集没有包括某用户的历史行为,则无法进行推荐的评价。
评价只具有客观性,没法获得客户的主观评价(真实评价更为重要)
难以找到离线评价指标和在线真实反馈(点击率、转化率、点击深度、购买客单价、购买商品类别等)之间的关联关系;
1.2 用户调查(User study)
通过一些真实用户,让他们在需要测试的推荐系统上完成一些任务。记录用户的行为,并让他们回答一些问题。最后,我们通过分析他们的行为和答案,了解测试系统的性能。
1、优点
可以获得用户主观感受的指标,出错后容易弥补;
2、缺点
招募测试用户代价较大(人工成本高);
无法组织大规模的测试用户,统计意义不足;
1.3 在线实验(online experiment)
在完成离线实验和用户调查之后,可以将系统上线做AB测试,将它和旧算法进行比较。
在线实验最常用的评测算法是【A/B测试】,它通过一定的规则将用户随机分成几组,对不同组的用户采用不同的算法,然后通过统计不同组的评测指标,比较不同算法的好坏。
1、A/Btest 核心思想
a) 多个方案并行测试;
b) 每个方案只有一个变量不同;
c) 以某种规则优胜劣汰。
A/B测试必须是单变量,在推荐系统的评价中,唯一变量就是 推荐的算法模型。
2、优点
可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标;
3、缺点
周期较长,必须进行长期的实验才能得到可靠的结果;
4、切分流量
大型网站做AB测试,可能会因为不同团队同时进行各种测试对结果造成干扰,所以切分流量是AB测试中的关键。
不同的层以及控制这些层的团队,需要从一个统一的地方获得自己AB测试的流量,而不同层之间的流量应该是正交的(不存在线性关系)
1.4 总结
一般来说,一个新的推荐算法最终上线,需要完成上述的3个实验。
首先,通过离线实验证明它在很多离线指标上优于现有的算法;
其次,通过用户调查确定用户满意度不低于现有的算法;
最后,通过在线AB测试确定它在我们关心的指标上优于现有的算法;
2 评测指标
当前推荐系统性能的评测有许多定性和定量的指标
2.1 预测准确度
度量推荐系统预测用户行为的准确度,可以离线实验下获取,对于学术研究有很大的用处,根据研究方向的不同,主要分为预测评分准确度和TopN推荐。
1) 预测评分准确度
通过预测结果和用户的实际评分的距离来进行度量,所以一般采用最常用的MAE和RMSE。
平均绝对误差(MAE)
均方根误差(EMSE)
Netflix认为均方根误差加大了对预测错误的用户物品评分的惩罚,所以更加严格,此外,如果一个评测采用整数评分,对预测结果取整数会降低MAE的误差。
2) TopN推荐
给用户推荐一个推荐列表,这就是TopN推荐,这也更符合实际的需求。一般采用准确率和召回率进行评测。T(u)是根据用户在训练集上的行为给用户做出的推荐列表,R(u)是用户在测试集上的行为列表。
准确率(precise)
召回率(recall)
2.2 用户满意度
顾名思义,只能通过用户调查和在线测试进行获取,无法离线实验获取。
用户调查:通过调查问卷,充分考虑用户的各方面体验,针对问题进行回答。
在线测试:一般情况下,可以采用用户点击率,停留时间,转化率进行度量。
2.3 覆盖率(coverage)
描述一个推荐系统对物品长尾的发掘能力,即是推荐出来的物品张总物品的比例。对于假设系统的用户集合为U,推荐系统给每个用户推荐一个长度为N的物品列表R(u),覆盖率公式为:
覆盖率是内容提供者关心的指标,覆盖率为100%的推荐系统可以将每个物品都推荐给至少一个用户。
除了推荐物品的占比,还可以通过研究物品在推荐列表中出现的次数分布,更好的描述推荐系统的挖掘长尾的能力。如果分布比较平,说明推荐系统的覆盖率很高;如果分布陡峭,说明分布系统的覆盖率较低。
信息论和经济学中有两个著名指标,可以定义覆盖率:
信息熵
基尼指数(Gini index)
是按照物品流行度p(i)从小到大排序的物品列表中第j个物品
评测马太效应
马太效应,是指强者越强,弱者越弱的效应。推荐系统的初衷是希望消除马太效应,使得各物品都能被展示给对它们感兴趣的人群。
但是,很多研究表明,现在的主流推荐算法(协同过滤)是具有马太效应的。评测推荐系统是否具有马太效应可以使用基尼系数。
如,G1是从初始用户行为中计算出的物品流行度的基尼系数,G2是从推荐列表中计算出的物品流行度的基尼系数,那么如果G1<G2,就说明推荐算法具有马太效应。
2.4 多样性
为了满足用户广泛的兴趣,推荐列表需要能够覆盖用户不同兴趣的领域,即需要具有多样性。
多样性描述了推荐列表中物品两两之间的不相似性。假设s(i,j)在[0,1]区间定义了物品i和j之间的相似度,那么用户u的推荐列表R(u)的多样性定义如下:
推荐系统整体多样性可以定义为所有用户推荐列表多样性的平均值:
2.5 新颖性
新颖性也是影响用户体验的重要指标之一。它指的是向用户推荐非热门非流行物品的能力。
评测新颖度最简单的方法,是利用推荐结果的平均流行度,因为越不热门的物品,越可能让用户觉得新颖。
此计算比较粗糙,需要配合用户调查准确统计新颖度。
2.6 惊喜度
推荐结果和用户的历史兴趣不相似,但却让用户满意,这样就是惊喜度很高。
目前惊喜度还没有公认的指标定义方式,最近几年研究的人很多,深入研究可以参考一些论文。
2.7 信任度
如果用户信任推荐系统,就会增加用户和推荐系统的交互。
提高信任度的方式有两种:
增加系统透明度
提供推荐解释,让用户了解推荐系统的运行机制。
利用社交网络,通过好友信息给用户做推荐
通过好友进行推荐解释
度量信任度的方式,只能通过问卷调查。
2.8 实时性
推荐系统的实时性,包括两方面:
实时更新推荐列表满足用户新的行为变化;
将新加入系统的物品推荐给用户;
2.9 健壮性
任何能带来利益的算法系统都会被攻击,最典型的案例就是搜索引擎的作弊与反作弊斗争。
健壮性(robust,鲁棒性)衡量了推荐系统抗击作弊的能力。
2011年的推荐系统大会专门有一个推荐系统健壮性的教程,作者总结了很多作弊方法,最著名的是行为注入攻击(profile injection attack)。就是注册很多账号,用这些账号同时购买A和自己的商品。此方法针对亚马逊的一种推荐方法,“购买商品A的用户也经常购买的其他商品”。
评测算法的健壮性,主要利用模拟攻击:
a)给定一个数据集和算法,用算法给数据集中的用户生成推荐列表;
b)用常用的攻击方法向数据集中注入噪声数据;
c)利用算法在有噪声的数据集上再次生成推荐列表;
d)通过比较攻击前后推荐列表的相似度评测算法的健壮性。
提高系统健壮性的方法:
选择健壮性高的算法;
选择代价较高的用户行为,如购买行为比浏览行为代价高;
在使用数据前,进行攻击检测,从而对数据进行清理。
2.10 商业目标
设计推荐系统时,需要考虑最终的商业目标。不同网站具有不同的商业目标,它与网站的盈利模式息息相关。
总结:
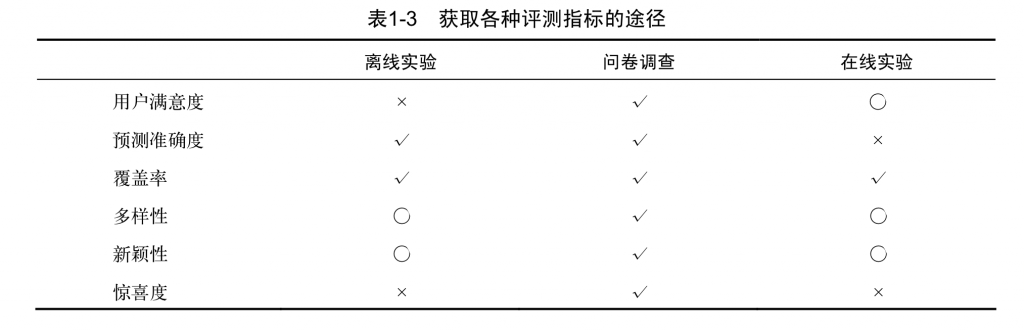
对于可以离线优化的指标,在给定覆盖率、多样性、新颖性等限制条件下,应尽量优化预测准确度。
3 评测维度
增加评测维度就是为了知道一个推荐算法在什么时候性能最好,一般评测维度分3种:
用户维度
主要包括用户的人口统计学信息、活跃度以及是不是新用户等;
物品维度
包括物品的属性信息、流行度、平均分以及是不是新加入的物品等;
时间维度
包括季节,是工作日还是周末,白天还是晚上等;
如果推荐系统的评测报告中,包含了不同维度下的系统评测指标,就能帮我们全面了解系统性能。
三、推荐系统架构
关于推荐系统的技术架构,我认为应该是作为一个初学者首先需要认识的。
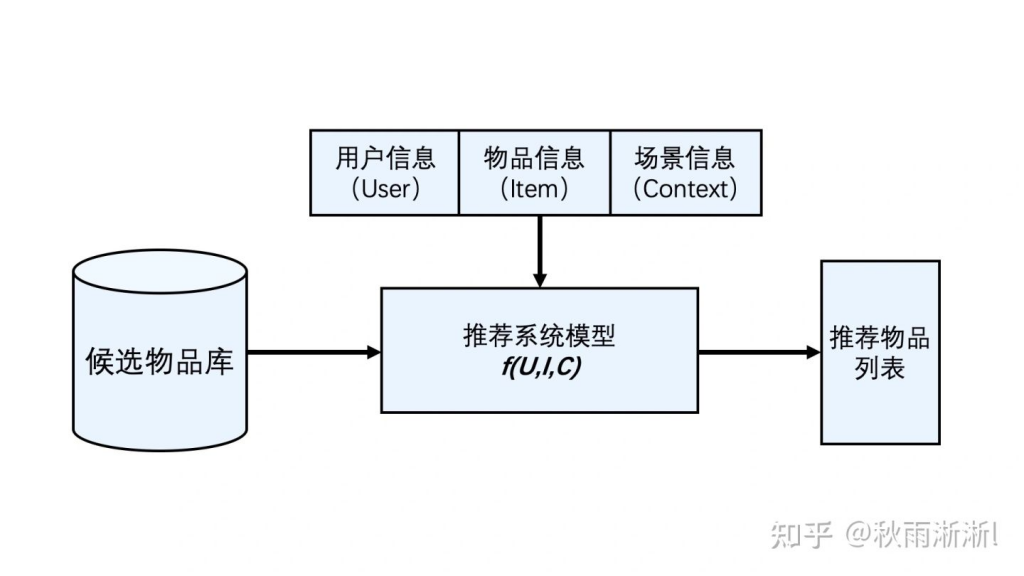
1 推荐系统架构图——baseline4
根据以上的很简单的架构图可以看出,一个推荐系统可以概括为f ( U , I , C ) f(U, I, C)f(U,I,C):基于用户(User)+物品(Item)+场景(Context)信息,从系统中的物品库中,给对应的用户推荐相应的物品,也即实现所谓的”千人千面“。
基于图文1.1,我们可以看到的推荐系统完成一次推断的流程为:
读取数据(ETL)
读取用户数据
读取物品数据
读取场景数据(实时上下文数据)
读取候选物品库数据(这里有很多召回的知识)
算法模型打分
有算法模型,意味着存在模型训练的过程推荐结果展示
按打分结果排序
2 Netflix的推荐系统架构图
这是Netflix发布了8年(2013年发布)之久的推荐系统架构。
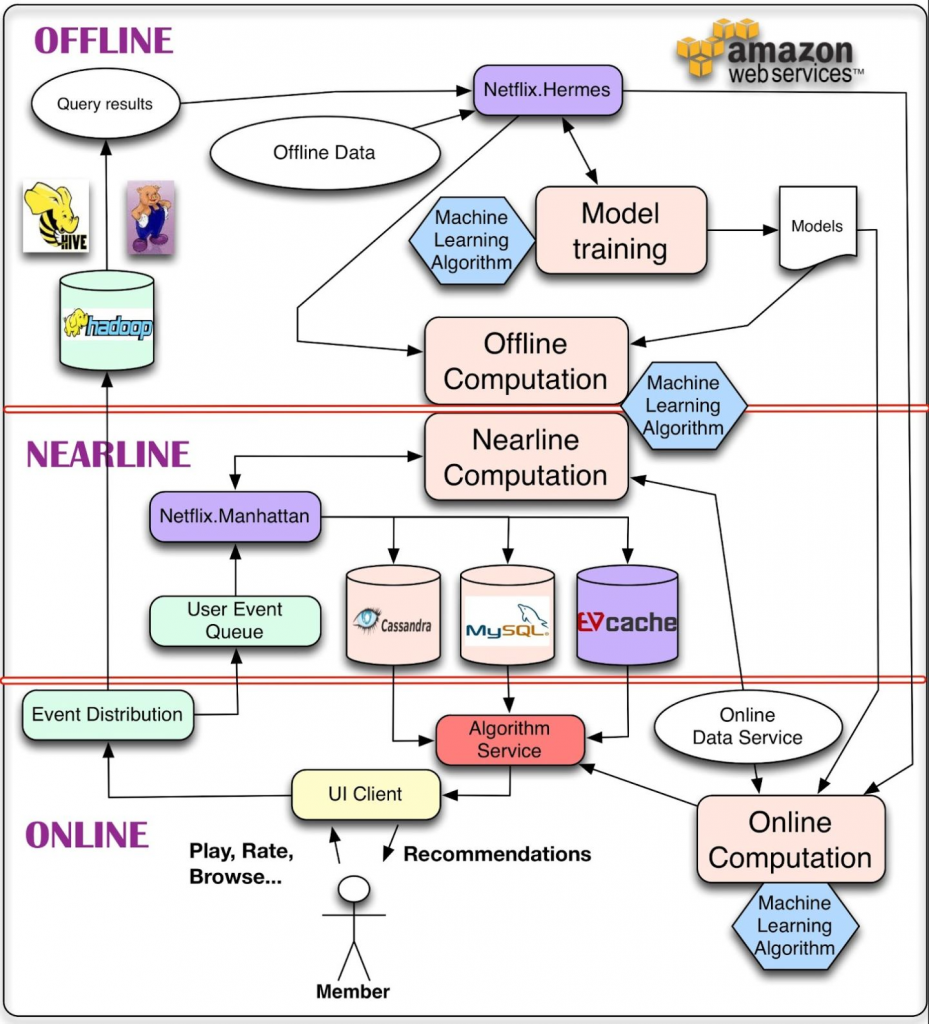
从上至下依次是离线(offline),近线(nearline)和在线(online)
2.1 离线
存储离线数据,利用大数据查询工具进行数据查询和处理,离线模型训练。离线部分对于数据数量和算法复杂度限制很少,以批量方式完成数据处理,但是数据处理的实时性非常差,无法做到数据和模型的即使更新。
可以看到当时还是hive,pig等工具的天下,现在spark 是主流,但也有越来越多的offline job被合并到near line之中,可以说当前的offline和nearline的界限日渐模糊了。
2.2 近线
基于数据消息队列,利用一些流计算平台进行数据的准实时处理。它居于离线和在线之间,既可以以分钟级别甚至秒级的延时来准实时地处理数据,也有一定的数据批量处理能力。
把算法模型所需要的特征数据,存储到读取时延更低的Cassandra/MySQL等中,在数据获取上减少推断时延。
定期更新(1分钟、半小时)算法模型所需要的特征数据,保证特征的实时性。
近线更新算法模型,提高模型实时性。
nearline可以说是近几年大数据架构发展的重中之重了。当时Netflix开发了自己的流处理框架Manhattan,但现在已经是Flink一统天下的时候,Netflix内部的Flink平台每天会运行上千个不同的流处理任务。涵盖了特征实时计算、数据监控、BI、模型实时训练等等。越来越多的offline任务被替代,也许Kappa架构彻底替代Lambda架构的日子不太远了。
2.3 在线
online部分的主要任务是进行用户请求的实时处理,模型的在线服务。在线部分需要更快地响应最近的事件和用户交互,因此对于延迟的要求比较苛刻,一般都要求在100ms以内完成所有处理,这会限制所用算法的复杂性和可处理的数据量。
正是online部分极高的响应延迟要求和相比离线、近线较弱的数据处理能力,要求online部分采用不同的高效的model serving方法去支持个性化推荐服务。
对于在线系统,一般要经过几个阶段,分别是召回,粗排和精排。
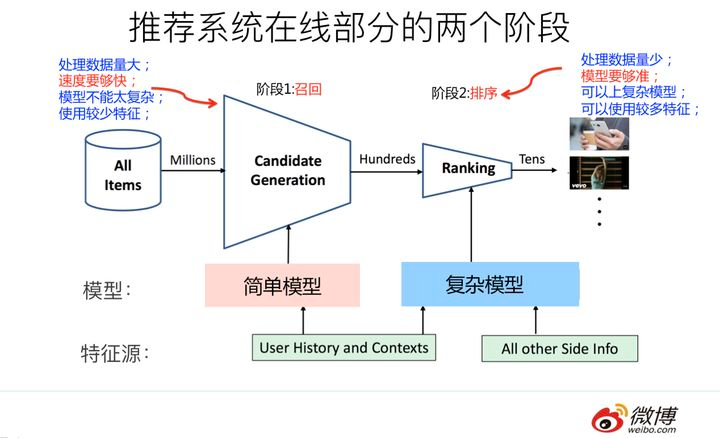
对于大多数推荐系统而言,在线系统的主体有召回(Recall)和精排(Ranking)。召回强调快,精排重视准。
召回:从千万量级的候选物品里,采取简单模型将推荐物品候选集合快速筛减到千级别甚至百级别
Ranking: 在候选集中,融入更多特征,使用复杂模型进行精确的个性化推荐。
进一步细分就有四个阶段:
四个环节分别是:召回、粗排、精排和重排。
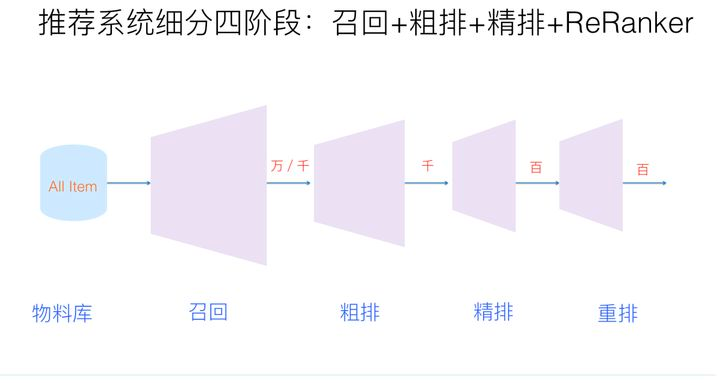
召回目的如上所述;有时候因为每个用户召回环节返回的物品数量还是太多,怕排序环节速度跟不上,所以可以在召回和精排之间加入一个粗排环节,通过少量用户和物品特征,简单模型,来对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的,可用可不同,跟场景有关。
之后,是精排环节,使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽量精准地对物品进行个性化排序。排序完成后,传给重排环节,传统地看,这里往往会上各种技术及业务策略,比如去已读、去重、打散、多样性保证、固定类型物品插入等等,主要是技术产品策略主导或者为了改进用户体验的。
2.4 推断流程
基于以上架构,我们可以对上文总结的推断过程进行一个扩充
读取数据(ETL)
读取用户数据(离线+近线+在线)
读取物品数据(离线+近线+在线)
读取场景数据(离线+在线)
读取候选物品库数据(在线)
算法模型训练
离线训练
近线迭代
算法模型打分
在线
推荐结果展示
在线
存储数据
记录用户和推荐系统的交互日志(在线+近线+离线)
至此,我们基本得到了一个工业级的推荐系统的推断流程。
3 技术栈
根据以上逻辑架构,我们可以构建一个推荐系统的技术栈
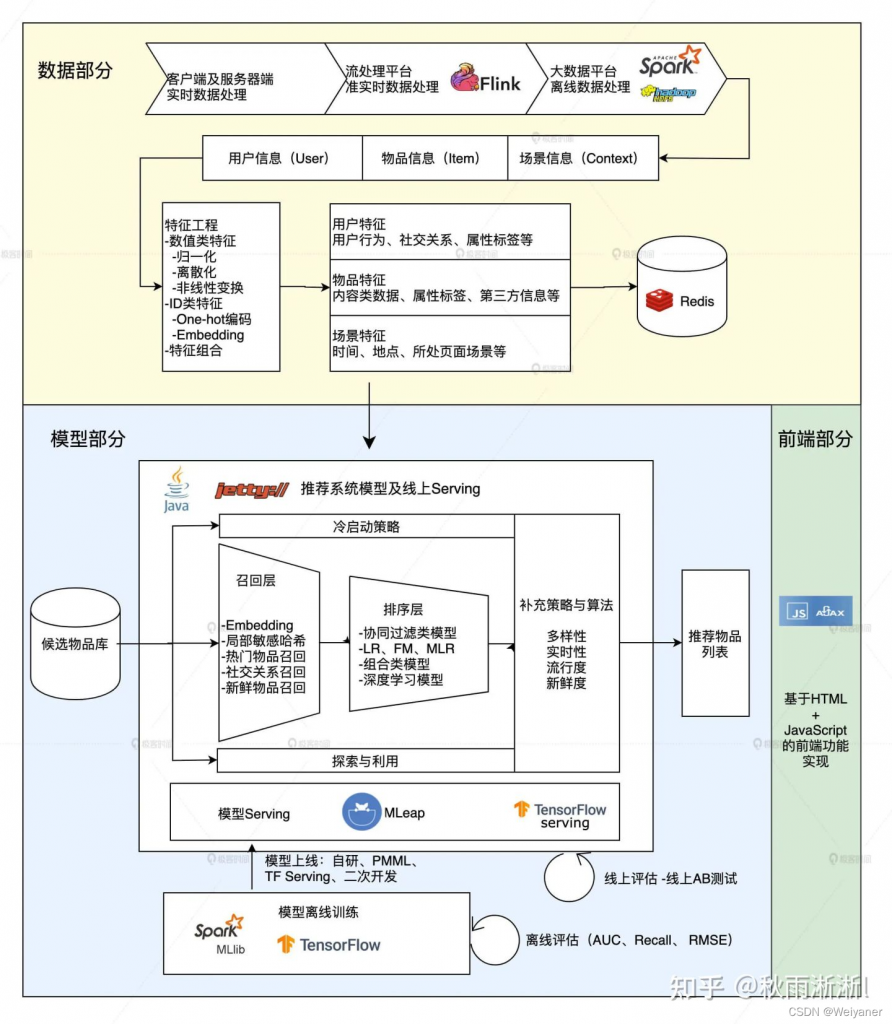
在数据ETL方面:
在数据采集上,可以采用流行的是Flink;
在离线批量计上,可以采用流行的是Spark;
在底层数据存储上,HDFS仍不过时;
在存储(U,I,C)的近线在线特征时,Redis能扛能打;
在模型推断方面:
算法层:
召回+排序
重排层
打散,在精排给出的准确性因子上增加多样性、新鲜度、流行度等因子冷启动推荐策略
算法工具层:
TensorFlow,算法开发成本直线下降
Spark MLlib,分布式计算你值得拥有
模型性能预估:
离线 AUC/Recall/RMSE
在线AB Testing
3.1 召回阶段
推荐系统的召回阶段是很关键的一个环节,但是对比如今的技术而言,该阶段的技术含量并不高,主要是偏策略导向的。如今推荐模型主流还是在研究排序阶段。
传统的召回阶段主要就是多路召回,下图所示。每一条策略就代表一个召回路线,所以说该阶段主要是偏策略方向。常用的召回策略基本都包括兴趣标签,兴趣Topic,兴趣实体,协调过滤,热门物品等等。多者高达几十路召回。

对于每一路召回,会拉回K条相关物料,这个K值是个超参,需要通过线上AB测试来确定合理的取值范围。如果你对算法敏感的话,会发现这里有个潜在的问题,如果召回路数太多,对应的超参就多,这些超参组合空间很大,如何设定合理的各路召回数量是个问题。
另外,如果是多路召回,这个超参往往不太可能是用户个性化的,而是对于所有用户,每一路拉回的数量都是固定的,这里明显有优化空间。按理说,不同用户也许对于每一路内容感兴趣程度是不一样的,更感兴趣的那一路就应该多召回一些,所以如果能把这些超参改为个性化配置是很好的,但是多路召回策略下,虽然也不是不能做,但是即使做,看起来还是很Trick的。
如果我们根据召回路是否有用户个性化因素存在来划分,可以分成两大类:
一类是无个性化因素的召回路
比如热门商品或者热门文章或者历史点击率高的物料的召回;
另外一类是包含个性化因素的召回路
比如用户兴趣标签召回。
我们应该怎么看待包含个性化因素的召回路呢?其实吧,你可以这么看,可以把某个召回路看作是:单特征模型排序的排序结果。意思是,可以把某路召回,看成是某个排序模型的排序结果,只不过,这个排序模型,在用户侧和物品侧只用了一个特征。比如说,标签召回,其实就是用用户兴趣标签和物品标签进行排序的单特征排序结果;再比如协同召回,可以看成是只包含UID和ItemID的两个特征的排序结果….诸如此类。我们应该统一从排序的角度来看待推荐系统的各个环节,这样可能会更好理解本文所讲述的一些技术。
如果我们换做上面的角度看待有个性化因素召回路,那么在召回阶段引入模型,就是自然而然的一个拓展结果:无非是把单特征排序,拓展成多特征排序的模型而已;而多路召回,则可以通过引入多特征,被融入到独立的召回模型中,找到它的替代品。如此而已。所以,随着技术的发展,在embedding基础上的模型化召回,必然是个符合技术发展潮流的方向。
在召回阶段,使用模型替换多路召回:链接
3.2 排序阶段
召回针对的是全部item,而精排针对的是召回输出的item。因此召回一般是在全部item集合上构建训练样本,而精排一般是基于展现样本来构建训练样本,解决基于单目标或者多目标的模型排序问题。最常见的就以CTR作为预测的预估算法。各行业也有不同的预测指标,比如电商的CVR(用户的转化率),阿里的一个主要排序目标就是gmv(ctr×cvr×price)。对于内容推荐,业务关心的除了CTR,还有阅读/观看时长、转发、评论等指标。
排序模型的发展史:
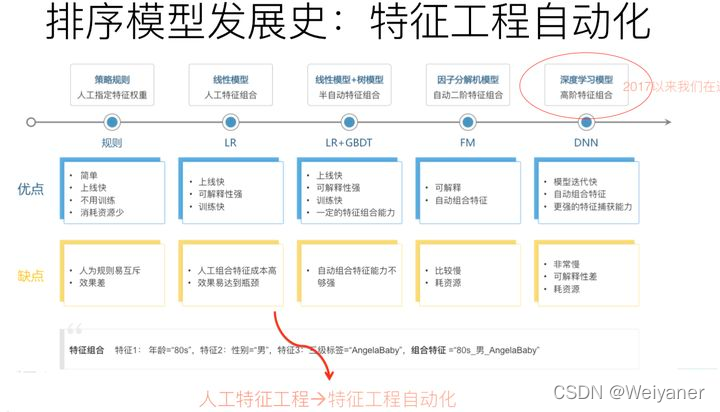
如果归纳下工业界CTR模型的演化历史的话,你会发现,特征工程及特征组合的自动化,一直是推动实用化推荐系统技术演进最主要的方向,而且没有之一。最早的LR模型,基本是人工特征工程及人工进行特征组合的,简单有效但是费时费力;再发展到LR+GBDT的高阶特征组合自动化,以及FM模型的二阶特征组合自动化;再往后就是DNN模型的引入,纯粹的简单DNN模型本质上其实是在FM模型的特征Embedding化基础上,添加几层MLP隐层来进行隐式的特征非线性自动组合而已。所谓隐式,意思是并没有明确的网络结构对特征的二阶组合、三阶组合进行直接建模,只是通过MLP,让不同特征发生交互,至于怎么发生交互的,怎么进行特征组合的,谁也说不清楚,这是MLP结构隐式特征组合的作用,当然由于MLP的引入,也会在特征组合时候考虑进入了特征间的非线性关系。
版权声明及安全提醒:本文转自网络平台,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:RyanLin007),谢谢!

