来源 | 字节跳动


一、治理背景
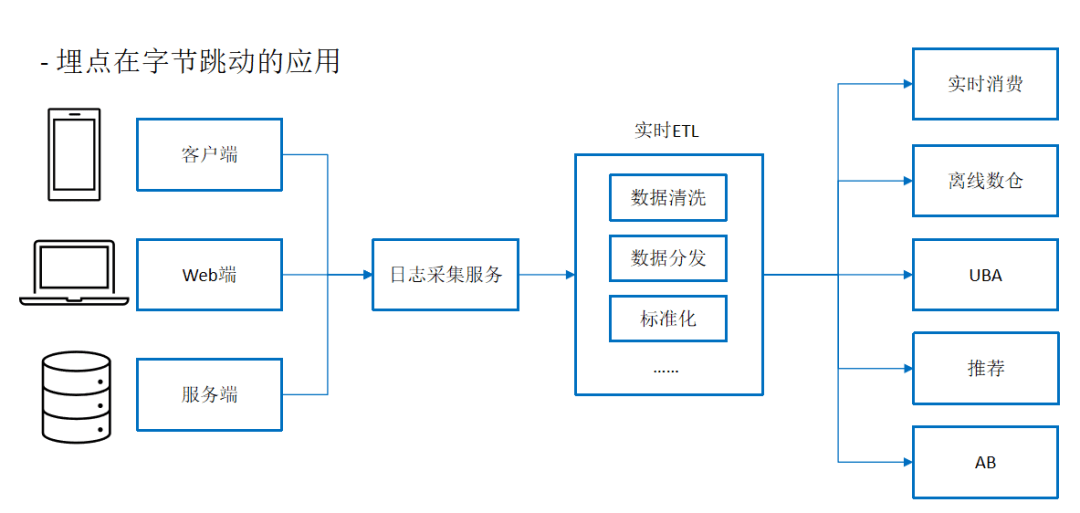
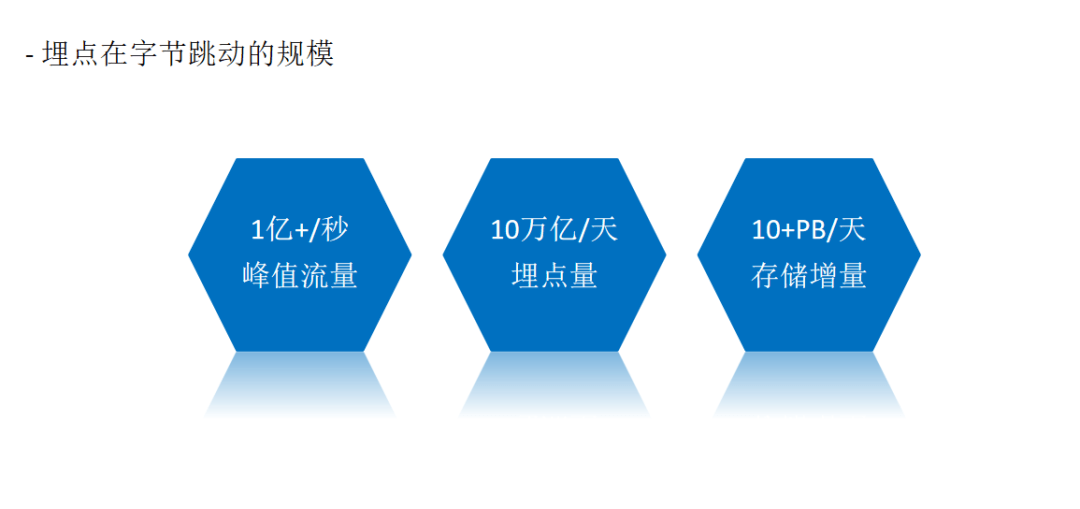
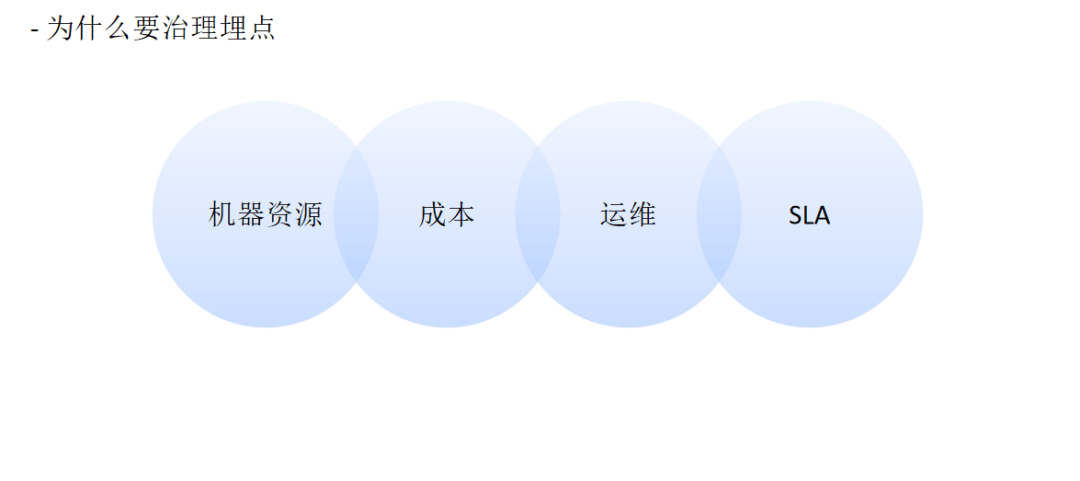
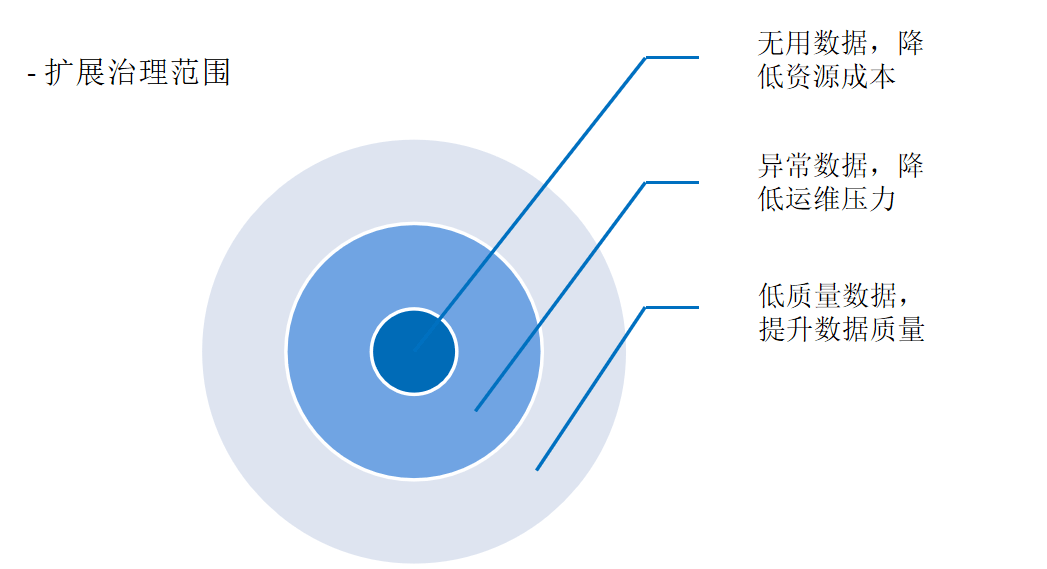
二、治理策略

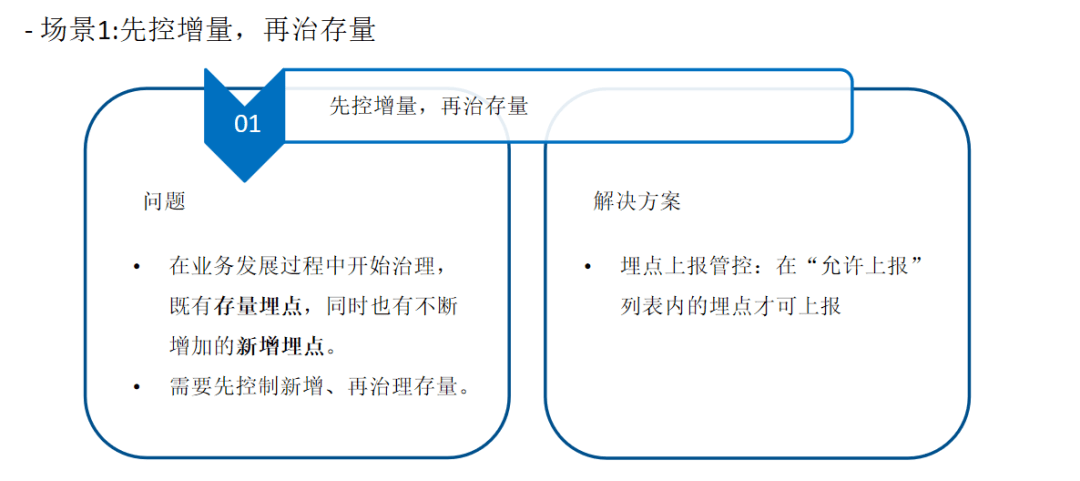
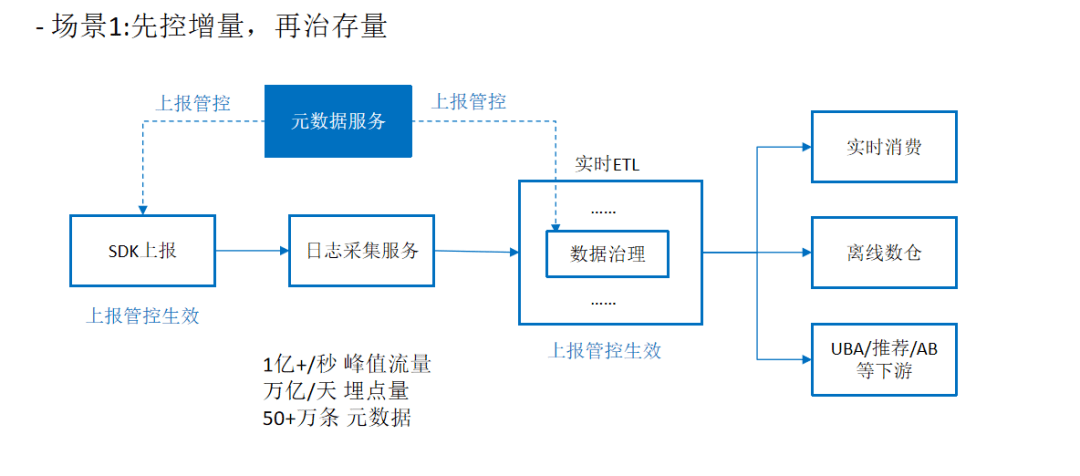

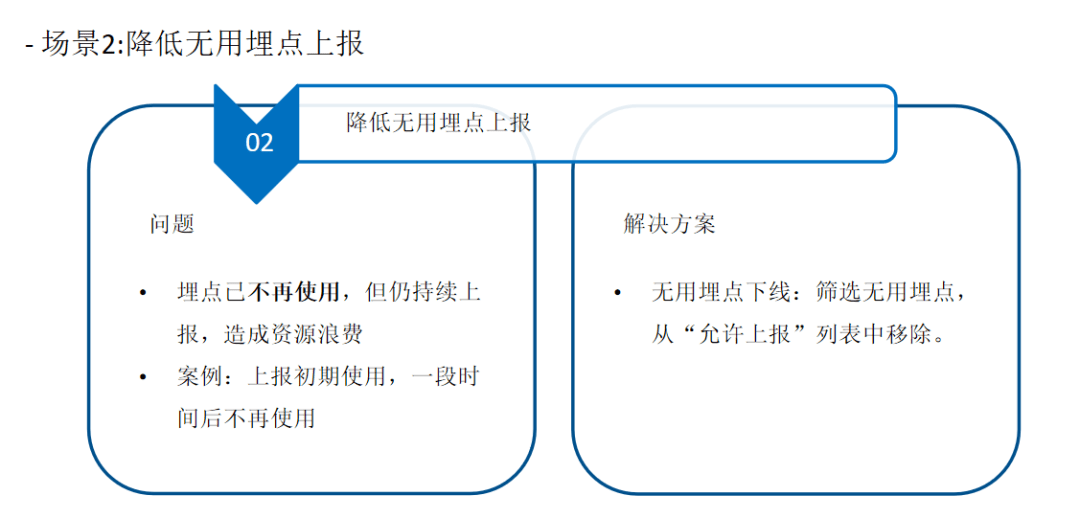
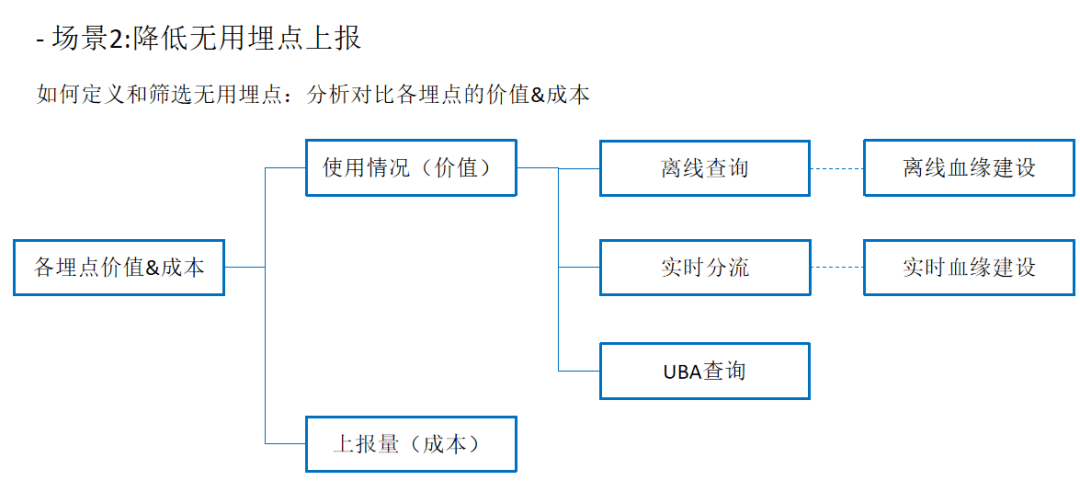

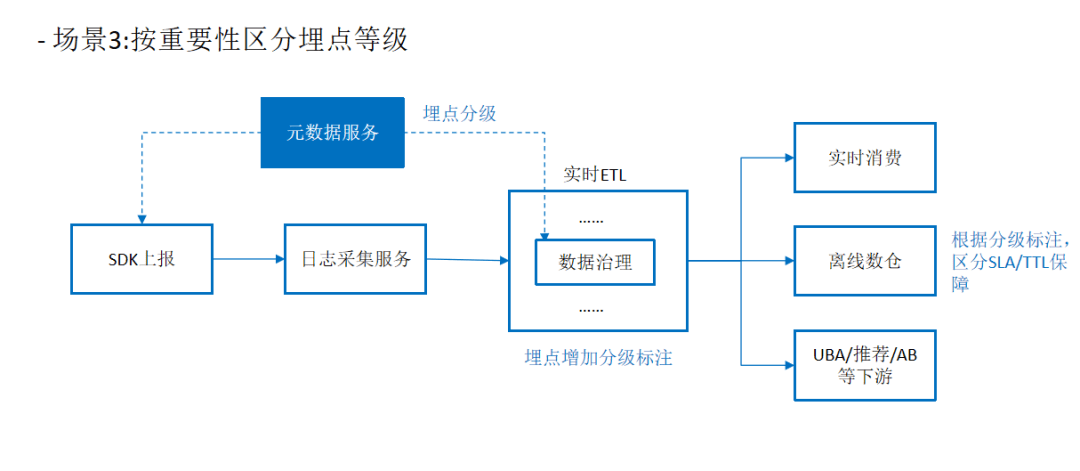
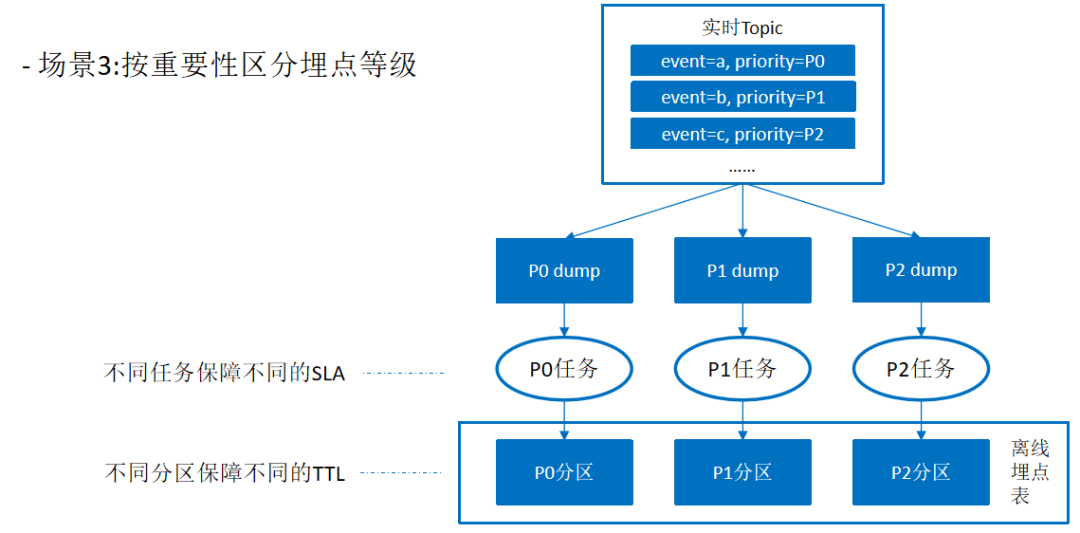
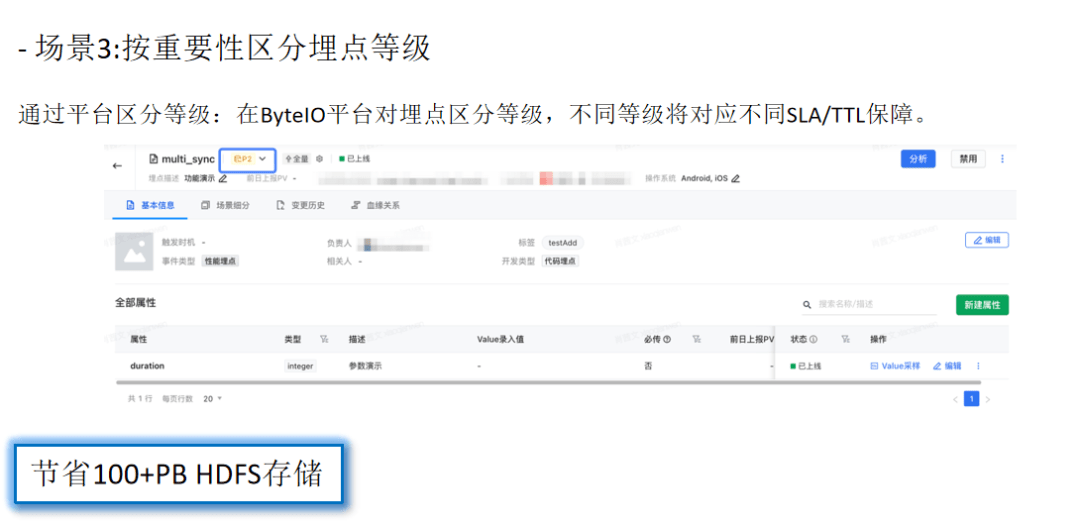
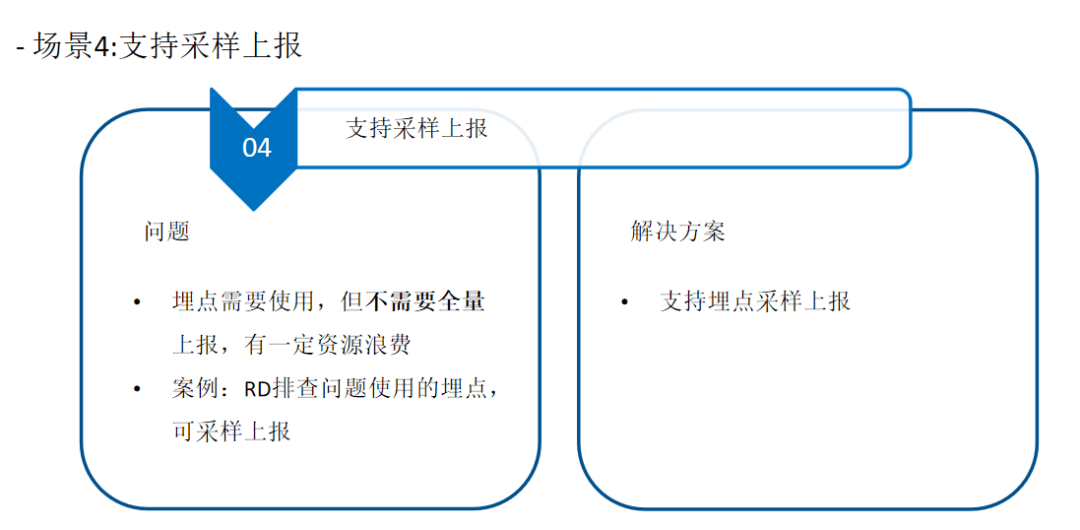
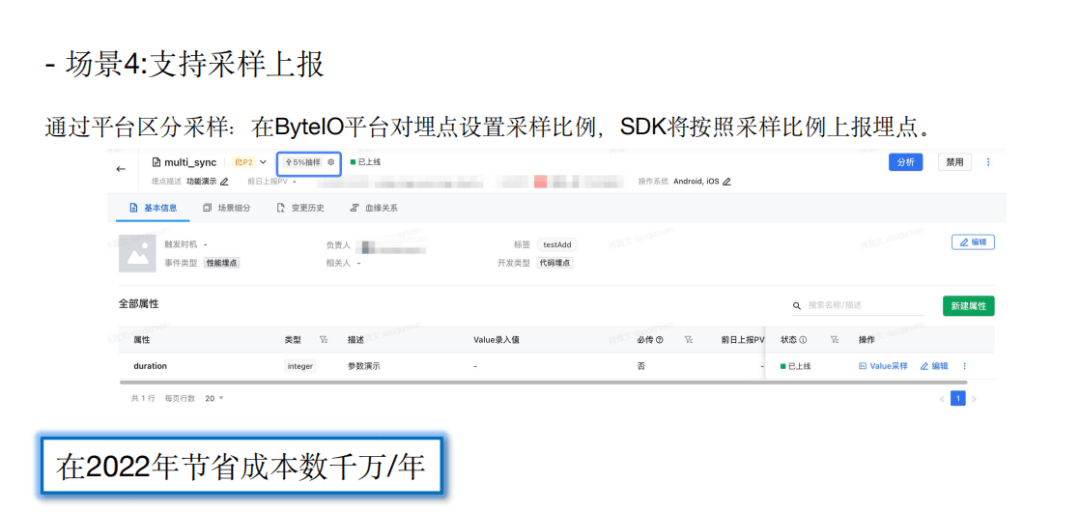
三、治理经验与回顾
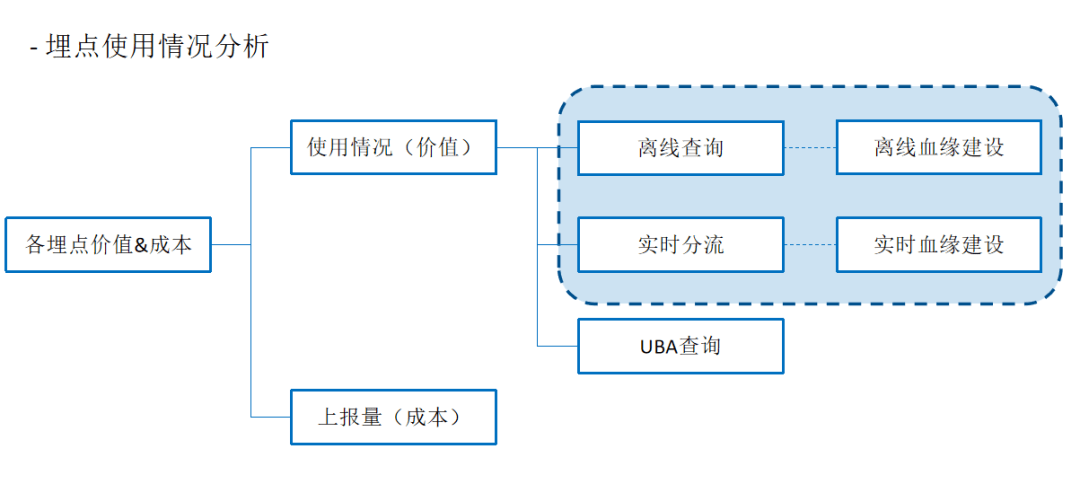
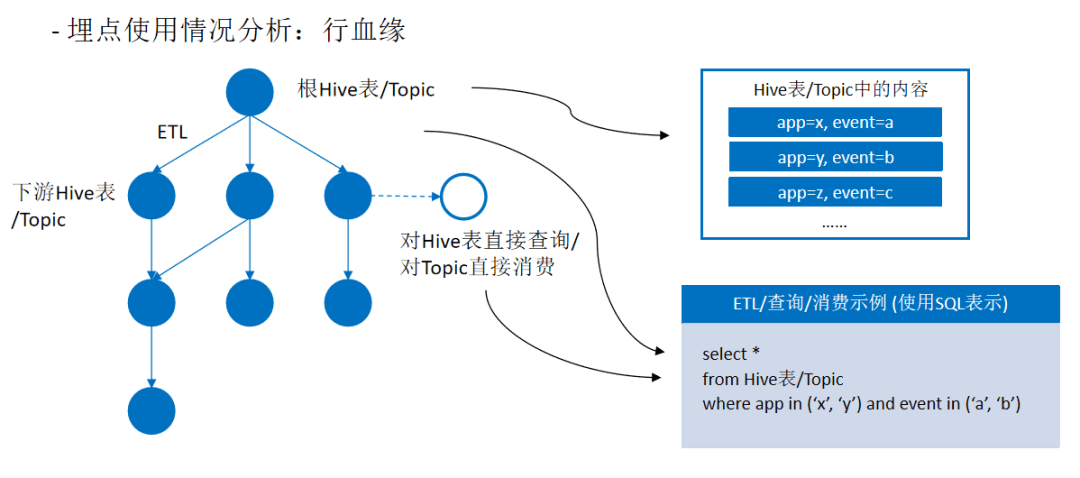
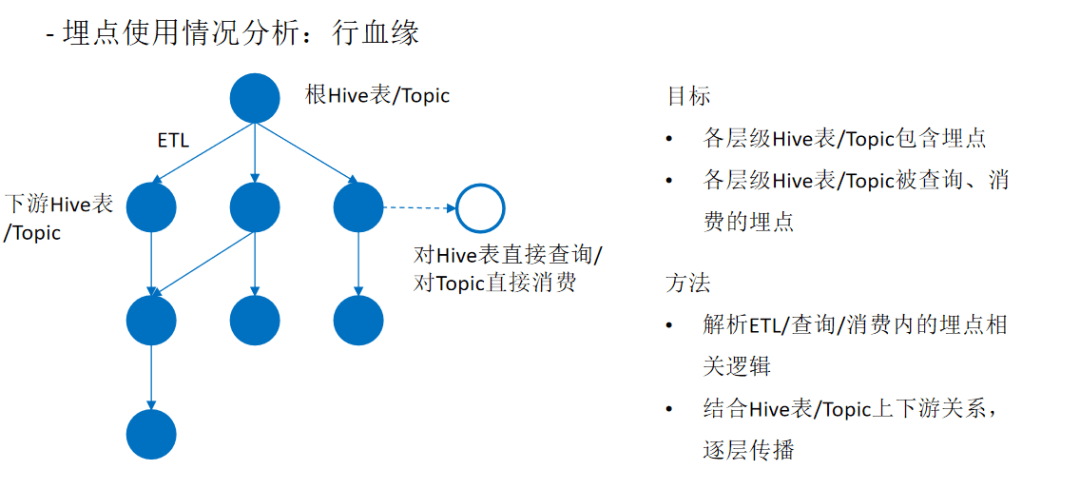
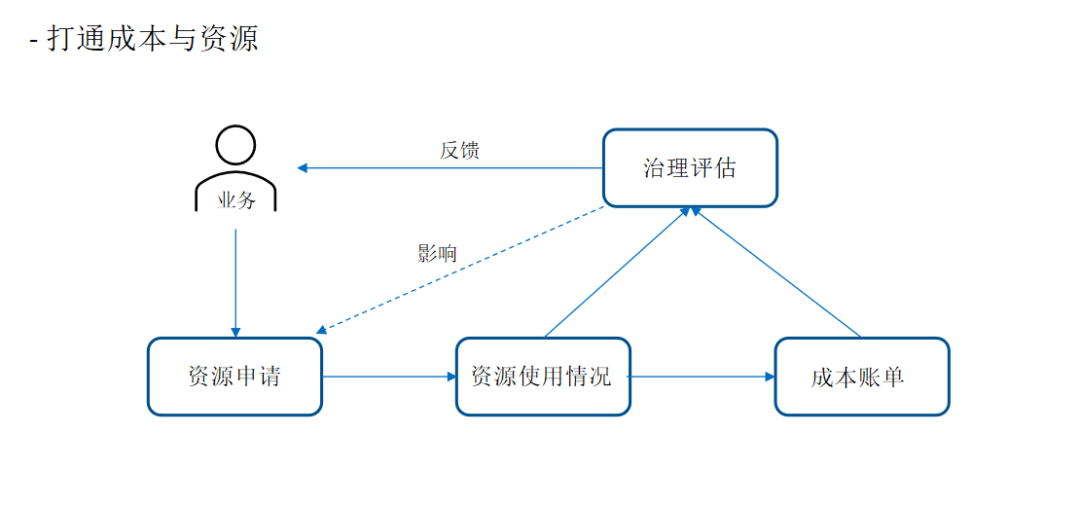
四、规划与展望

版权声明及安全提醒:本文转自网络平台,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:RyanLin007),谢谢!
来源 | 字节跳动
版权声明及安全提醒:本文转自网络平台,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:RyanLin007),谢谢!

数据治理与数据安全,本专辑包括数据治理、数据质量管理、大数据平台架构等培训与学习资料。
来源 | 数据治理体系 本文将通过两个步骤来介绍如何结合银行业金融机构的数据管理现状,搭建数据治理制度体系,激活各参与方的数据治理工作,形成常态化、科学化管理机制。这些步骤包括明确…

工商银行的数字化转型,是将数字元素纳入金融服务全流程、将数字思维贯穿业务运营全链条,实现金融生产方式和治理方式的变革。这就需要进一步提升数据的属性,推动其从资源化向资产化、资本化的…
德勤:银行业数据治理实践(163页),本专辑包括数据治理、数据质量管理、大数据平台架构等培训与学习资料。
银行数字化转型是银行业伴随金融科技发展的必然趋势,而数据治理是实现银行数字化转型的基础。
来源 | 银行家杂志 数据治理越来越受到银行、监管机构乃至国家层面的重视。银行已经意识到高效的管理体系、统一的数据标准、良好的数据质量才是数据价值实现的基础。在实践中,国内银行对于…