来源 | 金科创新社
项目背景及目标
随着客户规模的不断增长,以及全行业佣金率的逐步下行,如何更高效地对存量客户进行精细化运营管理已成为证券公司都在关注的重要问题。
过去一年多的时间里,结合相关业务场景和业务诉求点,利用大数据和机器学习,我们进行了多个业务模型的自研构建以及应用测试,并逐步地去进行系统化。项目的整体目标是以“客户为中心”、“从业务出发”,在对的时间,向有需求的客户提供与之匹配的服务或产品,让营销人员对客户的触达服务更高效和精准,线上线下结合,提升客户体验,目前已实现了包括羊毛党识别、客户分层、潜客挖掘、产品推荐、流失预警等在内的全生命周期客户数字化业务模型场景的构建,并形成了不断优化和正向反馈的迭代机制。
项目方案
本项目非独立建设系统,前端模块生产环境、测试环境分别依托于CRM和BI系统进行实现,后端管理和核心功能模块依托于大数据平台,触达模块以消息中心为主。
首先依托于大数据平台,通过客户历史数据构建针对某业务场景的数据模型,然后根据模型实现结果,分层推送到CRM/BI系统,并通过渠道回收数据,反哺模型,不断提升准确率。其次,利用数据仓库,在清洗和整合数据后,基于历史数据构建核心特征变量,为后续模型构建打好基础。
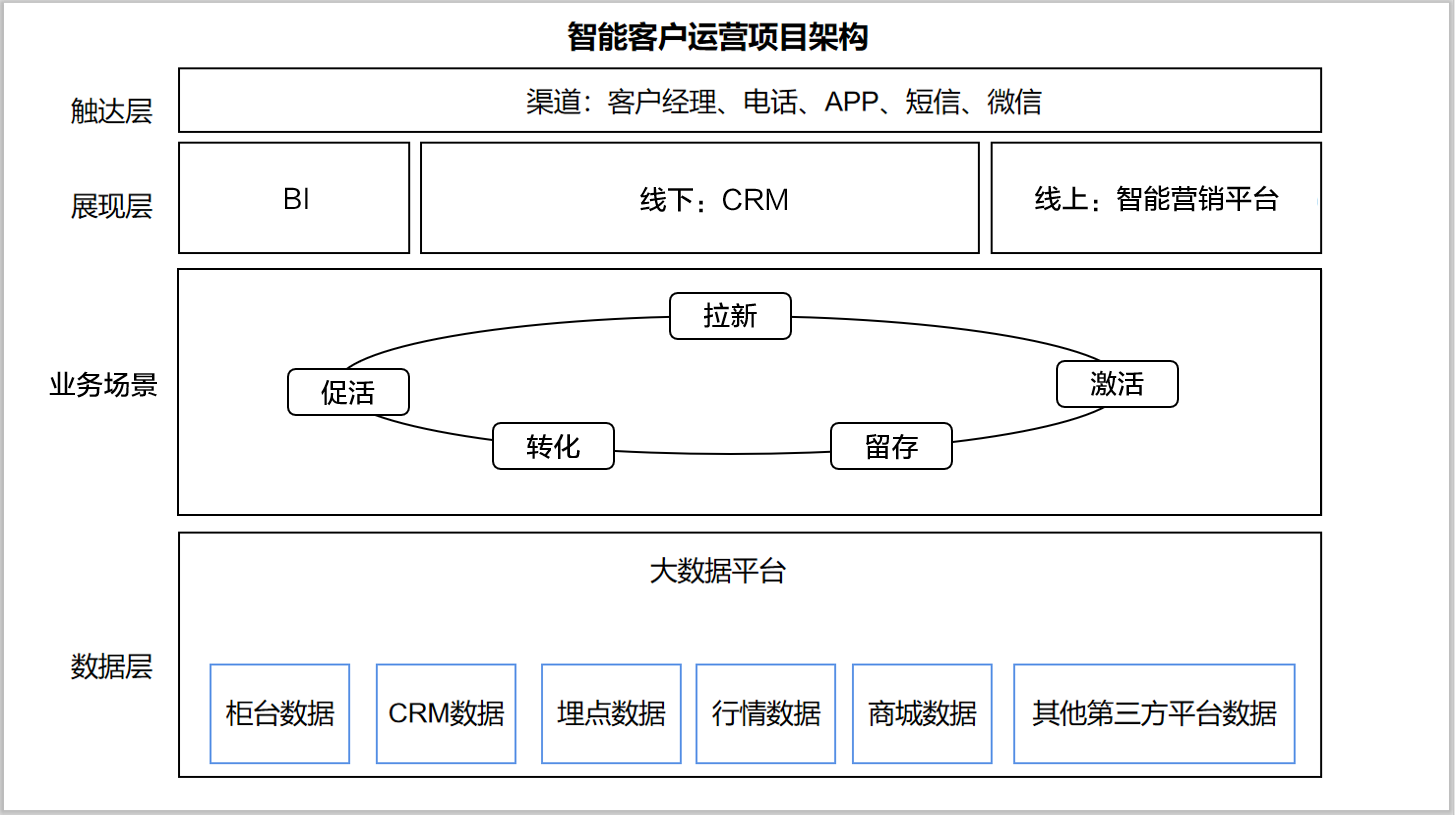

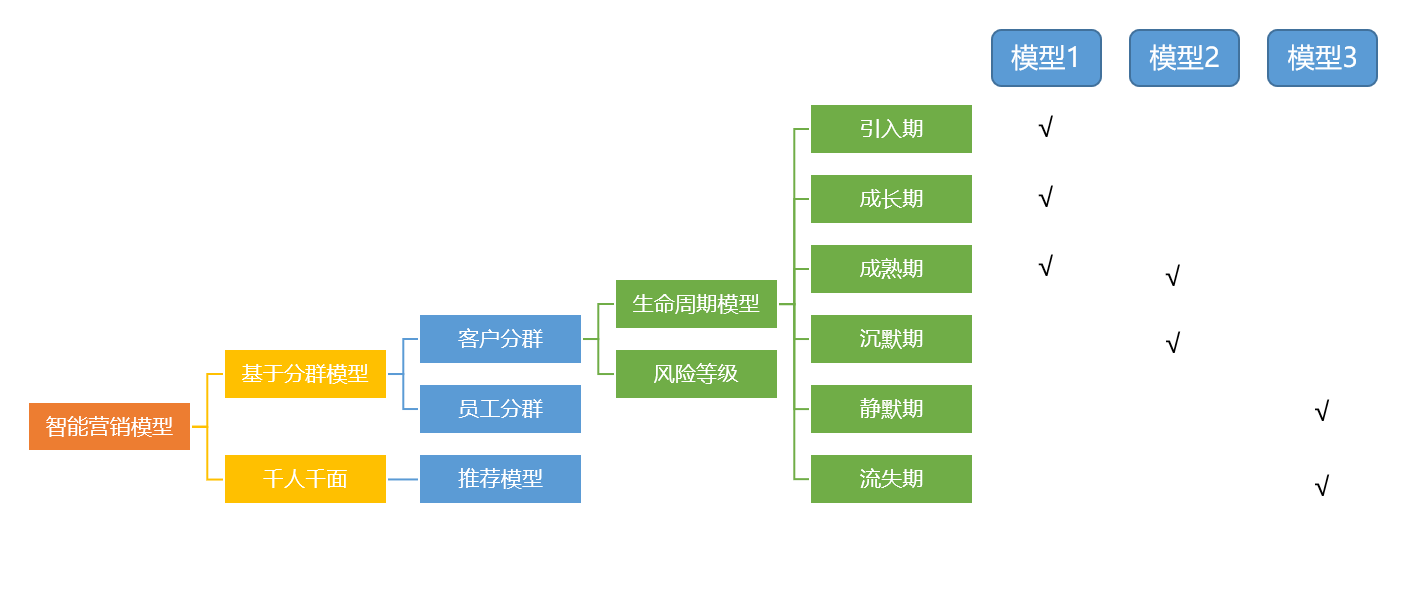
基于不同的生命周期阶段,我们将客户划分为了用户(游客或注册户)、新客户、活跃客户、沉默客户、流失客户,针对性地剖析客户的不同诉求以针对性地提供服务。
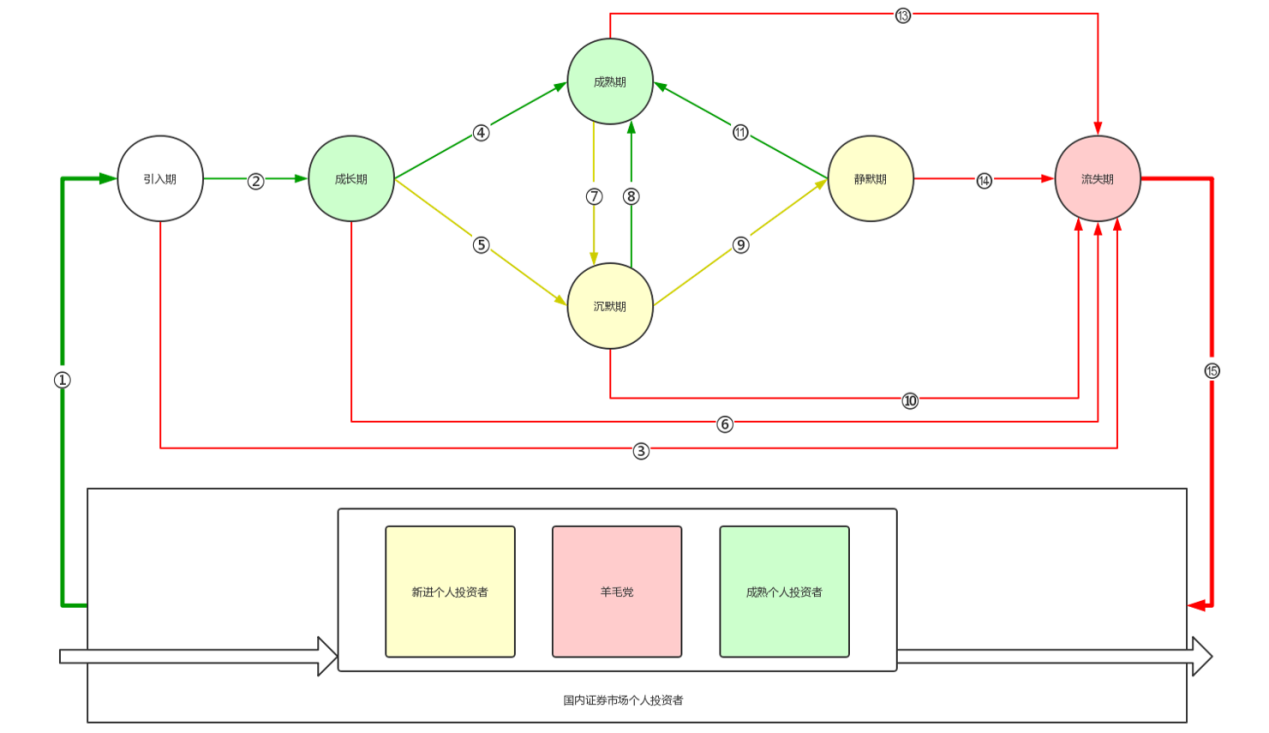
1、用户。对于游客或注册户,主要目标为开户转化,通过构建潜客挖掘模型预测关键行为转化率,在营销资源有限的情况下,线上线下结合,优先对转化概率较高的用户进行营销,提高资源利用率和精准度。
2、新客户。结合业务目标,关注促活,通过构建有效户等转化模型并给出推荐理由,帮助营销人员及时、快速识别潜客。
3、活跃客户。利用大数据平台内的多维度数据和客户特征,以交叉营销、预防沉默和流失为主要目标,结合具体场景中的其他业务数据,构建产品推荐、预沉默和预流失场景模型。
4、沉默和流失客户。对已进入到该阶段的客户,核心工作为沉默促活、流失挽回重新建立客户服务关系,这在实际业务开展中也是难度系数比较高的一项工作,主要借助历史数据和在外活跃情况挖掘出更易盘活的客户群体。
整个项目分为业务场景筛选、模型构建、可视化展示设计和试点营业部测试、正式开发和上线几个阶段,关联度不大的业务场景之间采用同步进行的方式。
项目创新点
1、所有业务模型均自研构建。本项目最核心的部分为各业务场景模型的构建,运用大数据建模思维和机器算法,充分挖掘大数据平台的历史存量数据和人工智能模型价值,根据我司客户的特点,全部采用自研的方式进行实现。
2、科学的复用和迭代机制。底层数据复用和流程的迭代机制,能同时兼顾实际业务效果和迭代速度,在一定程度上实现了客户服务效率和业务转化率的提升。
3、灵活的前端展示方式。前面提到本项目为非独立建设系统,一方面是为了节省系统资源、满足营销人员的使用习惯,另一方面也是为了让场景应用展示效果能更灵活,在实际业务中,便于根据不同的业务触达诉求选择在不同的业务终端系统中去进行实现。
技术实现特点
1、数据特征充分复用。账户和交易类数据是所有业务数据中质量和使用频率最高的数据类型,将其建设成完整数仓,并在其他业务场景中作为模型特征,实现复用。
2、模型充分复用。机器学习模型的构建在不同业务的相同场景下具有相同的流程,比如在业务类型A和B的获客场景中,都是以一段时间内已成功转化的客户作为正样本,以未转化的客户作为负样本,都是非常严重的不均衡数据集,且有较多相同的特征、相同的模型构建流程、参数调节流程,所以只需完善好一个其中一个业务场景的模型并将之模板化,就可以快速切换到同类型其他业务,充分实现模型复用,节省成本。
3、数据智能化。充分利用各类机器学习算法,结合专家规则构建特征变量,模型会随着数据变更和反哺不断再学习,能更适应业务发展变化,避免过多的人工干预并获得更高的准确率。
4、敏捷迭代与稳步上线保障。数据和模型的开发在后端搭建完成后,首先会生成初始模型,并在BI测试环境快速完成可视化测试展示,根据效果数据不断优化迭代,直至达到业务可接受的结果。测试完成后,选取有效的场景模型再在CRM(或员工APP)、智能营销平台(建设规划中)中进行实现,需要考虑在覆盖全量客户和营销人员的情况之下系统运行压力、时效性问题,达到稳定可用。
5、项目开发体系依托于大数据平台,可扩展性强。大数据平台的数据整合较全面、维度丰富、计算速度快,且可以直连BI,同时,搭建基于jupyter的开源开发平台,实现数据源对接hive、工作流对接azkaban、展现层对接BI,机器学习框架可随时扩展,能保证开发迭代的高效性。
项目过程管理
1、需求分析和概要设计
2019年4月-5月,完成业务需求分析、业务功能和技术构架的高层设计。提交了现状需求分析报告、各功能模块的高层设计、技术构架和接口的高层设计等文档。
2、需求和技术验证阶段
2019年5月-11月,进行业务场景设计,数据获取,数据分析,模型构建,模型验证,提交验证技术文档和验证效果文档。
3、系统编码、测试和上线准备阶段
2019年11月-2020年3月,完成后台数据编码、前端展现开发、测试以及试点行上线准备工作,提交系统工程文档和使用说明书。
4、营业部试点阶段
2020年3月-2020年8月,进行两批次八个试点营业部的测试使用,并根据反馈进行调优,同时对验证有效的场景逐步进行正式开发和上线,正向循环迭代。
5、正式上线阶段
2020年8月已安排部分业务场景正式上线,2020年9月计划将另外的业务场景逐步上线,并持续进行。
运营情况
从试点营业部测试到开发实现,目前已覆盖客户10万以上,涉及近10余个业务场景,随着前端功能的不断开发实现,以及业务场景的增加,覆盖客户数也将逐步增加,达成覆盖全量客户的目标。
项目成效
目前已完成了近10个模型场景的搭建,并通过了线下测试,一部分也已上线试运行,其中,从客户生命周期的维度将客户细分为了100多类,并对每一类客户进行了服务匹配策略探索。其中,业务A转化模型中,相比对照组,模型组的转化率提升了6倍左右;沉默和流失预警中,30天内预测准确率超过75%,召回率达到85%,每日挖掘流失线索500条以上。高价值客户挖掘中,和公司整体转化水平相比,模型效果提升了4倍。
经验总结
相比互联网公司,作为传统金融的证券行业,尤其是中小券商,在数据智能应用中有其独有的一些特点,比如客户的区域性、投入产出的考量等。通过各种尝试和摸索,我们探索到了一套可行有效的方法,逐步去帮助体量较大的营业部更高效地管理存量,减少低效的人力投入,并在公司财富管理转型的战略方向上,点滴地去输出和实践数字化、智能化,为未来客户增长带来的更多的存量,提前储备力量。
版权声明及安全提醒:本文转自网络平台金科创新社,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:RyanLin007),谢谢!

