什么是评分卡(信贷场景中)
- 以分数的形式来衡量风险几率的一种手段
- 对未来一段时间内违约/逾期/失联概率的预测
- 通常评分越高越安全
- 根据使用场景分为反欺诈评分卡、申请评分卡、行为评分卡、催收评分卡
为什么要开发评分卡
- 风险控制的一个环节,根据已有数据提供逾期概率指标参考
评分卡的特性
- 稳定性
- 预测能力
- 等价于逾期概率
评分卡开发的常用模型
- 逻辑回归
- 决策树
基于逻辑回归的评分卡理论依据
-
一个事件发生的几率(Odds),是指该事件发生的概率与该事件不发生概率的比值。若一个客户违约概率为p,则其正常的概率为1-p,由此可得:
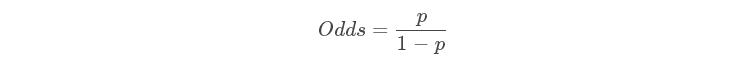

此时,客户违约的概率p可以表示为:
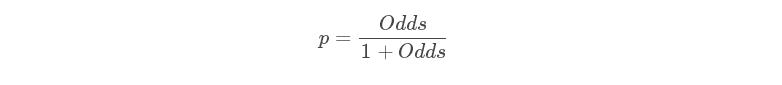
评分卡表达式为:
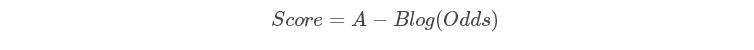
其中A、B为常数。由于log函数在(0→+∞)单调递增,所以当用户违约几率Odds越大时,Score评分越低。
通过给定
(1)某特定Odds时的Score值S0;
(2)该特定Odds值翻倍时Score增加值PD0;
通过给定值S0与PD0带入评分卡表达式,可求得A、B。
通过以上分析,求该用户评分Score的问题则转化为求用户违约对数几率log(Odds)的问题。
依照二元逻辑回归构造预测函数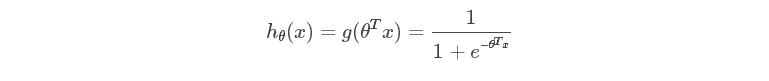
其中hθ(x)表示结果取1的概率。
推倒可得该事件的对数几率log(Odds)如下: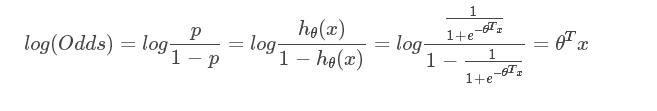
可以发现:在逻辑斯蒂回归模型中,输出Y=1的对数几率是输入条件x的线性函数。

回到信贷业务中
目标:寻找最理想的参数估计θ使得模型预测的概率相对已有样本最准确。
方法:损失函数最小化求得θ
逻辑回归的损失函数为对数损失函数(具体可由极大似然估计推倒):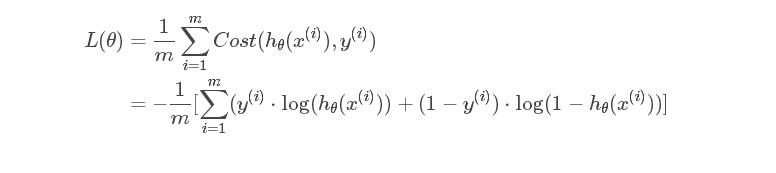
1.检验异常样本
根据对具体业务的理解和认识去除一些异常极端的数据。例如在对网页浏览量的分析,可能需要去除爬虫用户的浏览数据。
2.缺省字段的处理
数据样本的某些特征字段可能有缺省值,需根据缺省值多少与特征类型区分处理
- 缺省值很多时直接舍弃。作为特征加入的话,可能反倒带入噪声,影响最后的结果。
- 非连续特征缺省量适中时,将Nan作为一个新类别加入至特征中
- 连续特征缺省量适中时,考虑给定一个step(比如age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中
- 缺省值很少时利用填充的办法进行处理。例如用均值、中位数、众数填充,模型填充等
变量筛选
单变量:归一化,离散化,缺失值处理
多变量:降维,相关系数,卡方检验,信息增益。决策树等。
这里讲一种行业经常用的基于IV值进行筛选的方式。
首先引入概念和公式。
IV的全称是Information Value,中文意思是信息价值,或者信息量。
求IV值得先求woe值,这里又引入woe的概念。
WOE的全称是“Weight of Evidence”,即证据权重。
首先把变量分组,然后对于每个组i,对于第i组有:
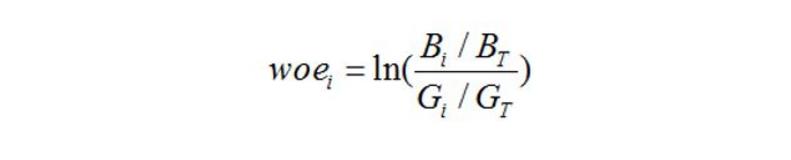
其中 是第i组坏客户数量(bad), 是整体坏客户数量。同理,G就是good,好客户的意思。 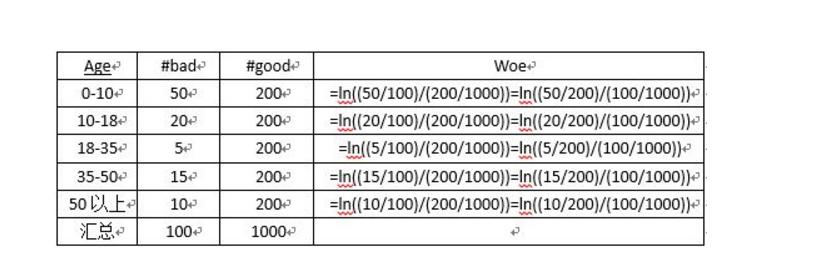 woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响而IV值得公式如下:
woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响而IV值得公式如下: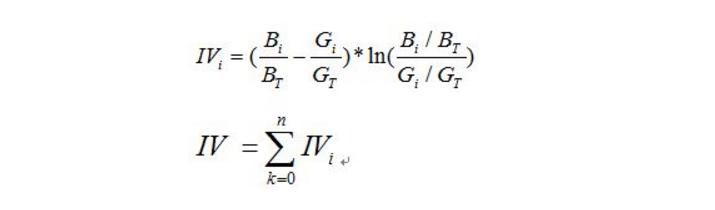
- 我们可以看到IV值其实是woe值加权求和。这个加权主要是消除掉各分组中数量差异带来的误差。比如如果只用woe的绝对值求和,如果一些分组中,A组数量很小,B组数量很大(显然这样的分组不合理),这是B的woe值就很小,A组很大,求和的woe也不会小,显然这样不合理。比如:
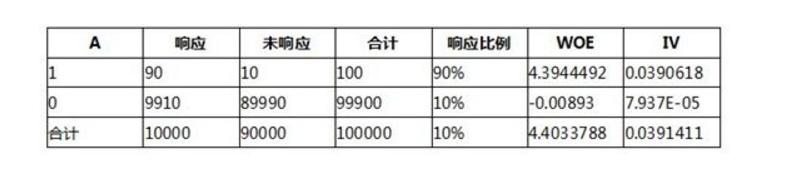
最后我们可以根据每个变量VI值的大小排序去筛选变量。VI越大的越要保留。变量处理
变量离散化:
评分卡模型用的是logistics,基本上都需要变量离散化后,效果才比较好。
离散化一般有几种方式:合并和切割。
合并:先把变量分为N份,然后两两合并,看是否满足停止合并条件。
切割:先把变量一分为二,看切割前后是否满足某个条件,满足则再切割。
而所谓的条件,一般有两种,卡方检验,信息增益。
关于这两种方法已经有很多介绍,不在赘述,大家可自行查阅相关资料。
模型优化
KS检验
- KS检验主要是验证模型对违约对象的区分能力,通常是在模型预测全体信用样本的信用评分后,将样本按违约率与非违约率分成两部分,然后用KS统计量来检验两组样本信用评分是否具有显著性差异。
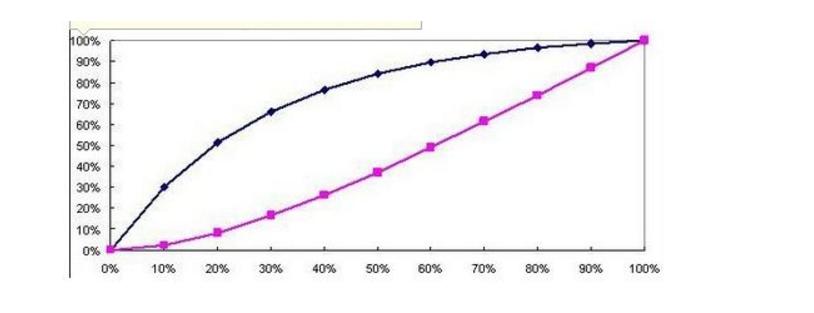 横轴是总体累积率,纵轴是各样本累积率蓝色是坏客户的占比,红色是好客户的占比,两者都会随着横轴总体累积率的变化而变。但两者差距最大时,为KS值。
横轴是总体累积率,纵轴是各样本累积率蓝色是坏客户的占比,红色是好客户的占比,两者都会随着横轴总体累积率的变化而变。但两者差距最大时,为KS值。如在60%的时候KS值取得最大,此时将模型里面算出的P值(odds)排序,往下取60%时的P值,将60时的P值作为新的阈值,效果往往会有所提升。
- 模型检验
- 1.KS值图上面说过,此处不再叙述。2.ROC曲线
召唤经典级交叉矩阵

(1)True Positive Rate,敏感度,召回率计算公式为TPR=TP/(TP+FN)(2)False Positive Rate,简称为FPR,计算公式为FPR=FP/(FP+TN)
(3)Precision=TP/(TP+FP),或2TP/((TP+FN)+(TP+FP))。
(4)真负类率(True Negative Rate,TNR),也称为specificity,计算公式为TNR=TN/ (FP+ TN) = 1 – FPR。
- ROC曲线及AUC系数主要用来检验模型对客户进行正确排序的能力。ROC曲线描述了在一定累计好客户比例下的累计坏客户的比例,模型的分别能力越强,ROC曲线越往左上角靠近。AUC系数表示ROC曲线下方的面积。AUC系数越高,模型的风险区分能力越强。3.Lift曲线
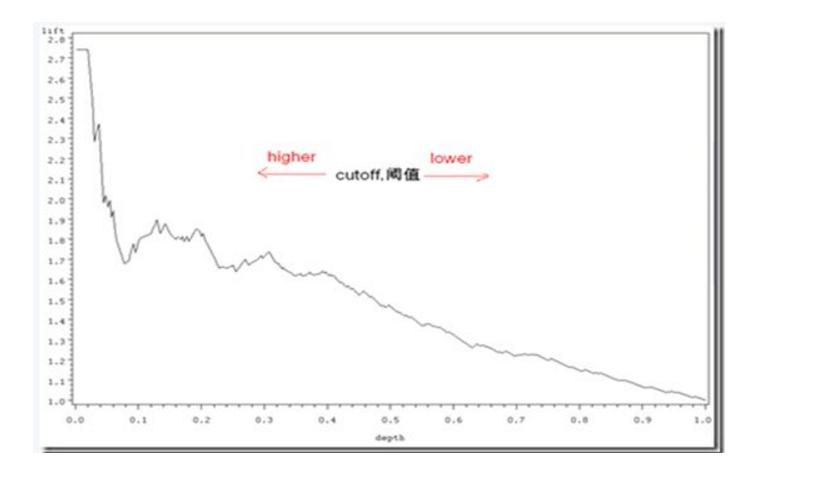
Lift=命中率/真实中正例的比例横坐标Depth为预测成正例的比例
在模型中,随着改变阈值p,命中率会随之改变,lift曲线中横坐标就是改变阈值p下正比例的变化,纵坐标是lift提升度。比如命中率是80%,原来好坏比是1.1,那样就提高了1.6。
一般来说,在depth为1前,lift越大于1越好。
- 总结
- 在实际建模中需要重复特征工程、变量离散化、KS检验等步骤,不断优化以达到更优效果。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本文链接:https://blog.csdn.net/htbeker/article/details/79697557
版权声明及安全提醒:本文转自网络平台CSDN,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:RyanLin007),谢谢!

